데이터 분석한 지 너무 오래 되었는데, 조만간 다시 하게 될 것 같아 공부 중. 기초도 다 까먹어서 새롭다.. 하아..
Kaggle의 은행 이동 예측하는 예제로 다시 감을 잡기 시작한다.
Binary Classification with a Bank Churn Dataset | Kaggle
www.kaggle.com
전처리를 한다고 결과가 달라지는 예제가 아니긴 하지만, Step-by-Step으로 해 보기로 한다.
import pandas as pd
train = pd.read_csv("train.csv")
train.hist(bins=25, figsize=(16, 10))

문자형 변수(Gender, Geography)를 제외한 숫자형 변수들의 특징을 보면 CreditScore, Age, Balance, EstimatedSalary가 연속형이고, 나머지는 이산형이다.
단순히 문자형 변수만 카테고리로 만들어서 학습하여 결과를 본다.
train['Geography'] = train['Geography'].astype('category').cat.codes
train['Gender'] = train['Gender'].astype('category').cat.codes
# 아무 처리하지 않고 Text 항목만 Category로 바꾸어서 X, y를 만듦
X = train[["Geography", "Gender", "Age", "Balance", "NumOfProducts", "HasCrCard", "IsActiveMember", "Tenure", "CreditScore", "EstimatedSalary"]]
y = train["Exited"]
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_auc_score
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
def train_lgbm(X, y):
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
params = {'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'binary_logloss',
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5}
# LGBM으로 분류
model = lgb.LGBMClassifier(**params)
model.fit(X_train, y_train, eval_set=[(X_test, y_test)], eval_metric='auc')
y_pred = model.predict_proba(X_test)[:,1]
return model, y_pred
model, y_pred = train_lgbm(X_train, y_train)
# AUC 예측
auc_val = roc_auc_score(y_test, y_pred)
print('AUC:', auc_val)
# 정확도 예측
y_pred = (y_pred >= 0.5).astype(int)
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy:', accuracy)
결과가 꽤나 훌륭하다. Ranker들의 AUC가 90%를 간신히 넘으니, LightGBM이 얼마나 우수한 알고리즘인지 알 수 있다.
AUC: 0.8904408955688136
Accuracy: 0.8672705789680977
그래도, Step-by-Step으로 안간힘을 써보자.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
def get_vectors(df_train, col_name):
vectorizer = TfidfVectorizer(max_features=1000)
vectors_train = vectorizer.fit_transform(df_train[col_name])
#Dimensionality Reduction Using SVD ( Singular Value Decompostion)
svd = TruncatedSVD(2)
x_sv_train = svd.fit_transform(vectors_train)
# Convert to DataFrames
tfidf_df_train = pd.DataFrame(x_sv_train)
# Naming columns in the new DataFrames
cols = [(col_name + "_tfidf_" + str(f)) for f in tfidf_df_train.columns.to_list()]
tfidf_df_train.columns = cols
# Reset the index of the DataFrames before concatenation
df_train = df_train.reset_index(drop=True)
# Concatenate transformed features with original data
df_train = pd.concat([df_train, tfidf_df_train], axis="columns")
return df_train
train = get_vectors(train,'Surname')
위의 코드는 Column 중에서 'Surname' (성)을 빈도에 따라서 벡터화하고, 2차원 상에 Mapping하여 특이값을 분해한 데이터를 만든다. 중요하지 않은 것일 수는 있는데, 외국에서는 친척끼리 근처에 몰려 사는 경우도 많기도 하니까.
import numpy as np
train['Senior'] = train['Age'].apply(lambda x: 1 if x >= 60 else 0)
train['AgeCat'] = np.round(train.Age/5).astype('int').astype('category')
train['IsActive_by_CreditCard'] = train['HasCrCard'] * train['IsActiveMember']
Age만으로도 충분할 수 있지만, 상식적으로 은퇴연령이 은행 이동에 영향을 줄 수 있으므로 Senior를 구분하였고, 연속형은 Age를 5살 단위로 구분하였다. 신용카드 보유여부와 사용하는 지를 Mapping했다.
from sklearn.preprocessing import StandardScaler, LabelEncoder, MinMaxScaler
numeirc_cols = ['Age', 'CreditScore', 'Balance','EstimatedSalary']
#Use Loop Function
for col in numeirc_cols:
sc = MinMaxScaler()
train[col+"_scaled"] = sc.fit_transform(train[[col]])
연속형 데이터들의 Scale을 맞춰준다. 범위들이 제가각이면 때로는 좋은 성능을 보장하기 어렵다.
X = train.drop(["id", "CustomerId", "Surname", "Age", "CreditScore", "EstimatedSalary",
"Balance", "Exited"], axis=1)
y = train["Exited"]
무의미하거나 중복된 데이터들을 제거하고, X, y를 나눈다.
df_corr = X.copy()
from sklearn.preprocessing import StandardScaler, LabelEncoder, MinMaxScaler
import seaborn as sns
import matplotlib.pyplot as plt
plt.subplots(figsize=(15,15))
palette = ["#764a23","#f7941d","#6c9a76","#f25a29","#cc4b57"]
palette_cmap = ["#6c9a76","#cc4b57","#764a23","#f25a29","#f7941d"]
sns.heatmap(df_corr.corr(), cmap = palette_cmap, square=True, cbar_kws=dict(shrink =.82),
annot=True, vmin=-1, vmax=1, linewidths=3,linecolor='#e0b583',annot_kws=dict(fontsize =8))
plt.title("Pearson Correlation Of Features\n", fontsize=25)
plt.show()
변수들간의 연관성을 살펴보면, 새로 생성한 변수들을 제외하고는 서로 관계가 크지 않아 보인다.
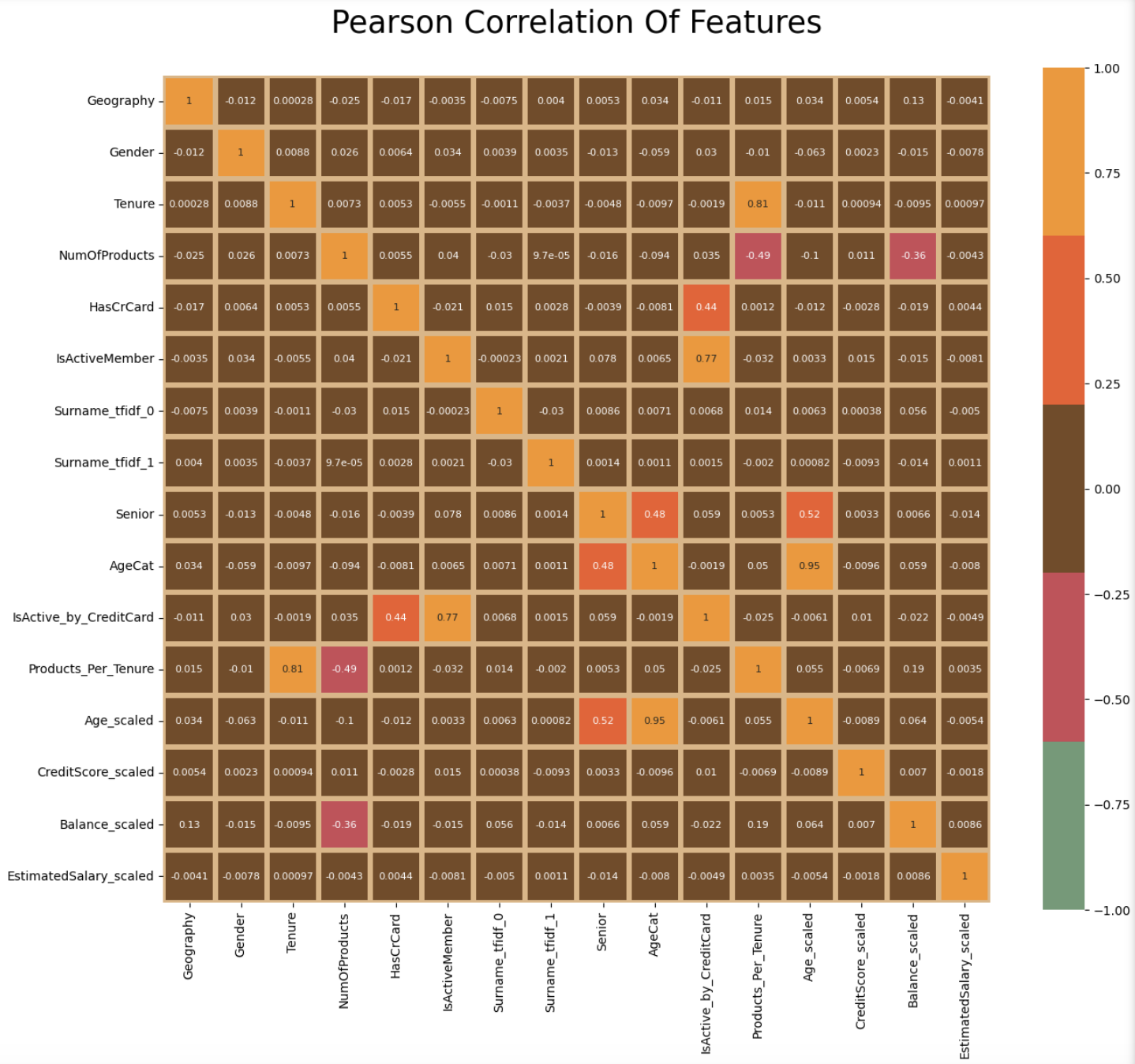
있는 그대로 학습해도 큰 무리는 없어 보인다.
AUC: 0.8922287344792802
Accuracy: 0.866694943496834
위에 사용했던 학습 코드를 그대로 적용 해 보면 AUC가 아주 살짝(0.2%) 올라갔다.
어떤 변수가 영향을 미쳤는 지도 알아보자.
lgb.plot_importance(model, importance_type="gain", figsize=(8,6), max_num_features=12,
color = "black", title="LightGBM Feature Importance (Gain)")

역시나 나이가 가장 크게 영향을 미친다. Senior 구분이 아예 포함되지 않은 것도 특이하다.
좋은 결과를 얻기 위한 것이 아니라 Step-by-Step 분석 방법을 복기하기 위한 정도로 이해하면 된다.
'AI 빅데이터 > 후려치는 데이터분석과 AI 알고리즘' 카테고리의 다른 글
| [자연어분석] BERT, Transformer, Self Attention 후려치기 (1) | 2023.01.28 |
|---|---|
| [데이터보안] LDP ( Local Differential Privacy) (0) | 2023.01.20 |
| [자연어분석] Seq2Seq에 Attention 활용하기 (0) | 2021.11.30 |
| [이상탐지] Exponential Smoothing을 활용한 이상탐지 (0) | 2021.02.14 |
| [데이터분석] Feature Engineering 7가지 팁 (0) | 2021.01.11 |




댓글