RNN 혹은 LSTM과 같은 순차적 모델을 활용해, 언어를 번역하는 것은 아래 포스팅해서 해봤다.
[자연어 처리] Seq2Seq 로 자연어 번역하기
언어 처리를 위해서는 시계열성이 반영되는 RNN이나 LSTM, GRU등을 사용해왔다. Seq2Seq는 Machine Translation을 위해 구글이 개발한 알고리즘으로 위의 알고리즘을 Encoder와 Decoder로 연결하여 하나의 벡터
magoker.tistory.com
하지만, 단순히 Seq2Seq를 사용하는 것에는 아래의 문제가 존재한다.
- 입력 Sequence가 매우 길면, 처음에 나온 Token 정보가 희석된다.
- Context Vector 사이즈가 고정되어 있어, 긴 Sequence 정보를 담기가 어렵다.
- 모든 Token이 영향을 주게 되므로, 중요하지 않은 Token도 영향을 준다.
생각해보면, 우리가 대화할 때 모든 단어마다 주의를 기울이지 않는다. 중요한 단어, 그리고 단어가 사용된 방식에 따라 의미 뿐 아니라 강조점 등을 파악할 수 있다. 이렇게 중요한 정보에 집중하게 만드는 것이 Attention Mechanism이다.
Attention의 핵심은 Context Vector를 하나로 Fix하지 않는, 즉 Dyanmic Context Vector에 있다. Context Vector를 RNN의 최종결과만으로 구성하는 Seq2Seq에 비해, Attention 모델에서는 Decoder에서의 단계별 Vector 값을 Hidden Layer 연산에 같이 사용함으로써, 다음 결과를 도출할 때 어느 단어에 집중할 지를 알려주게 된다.
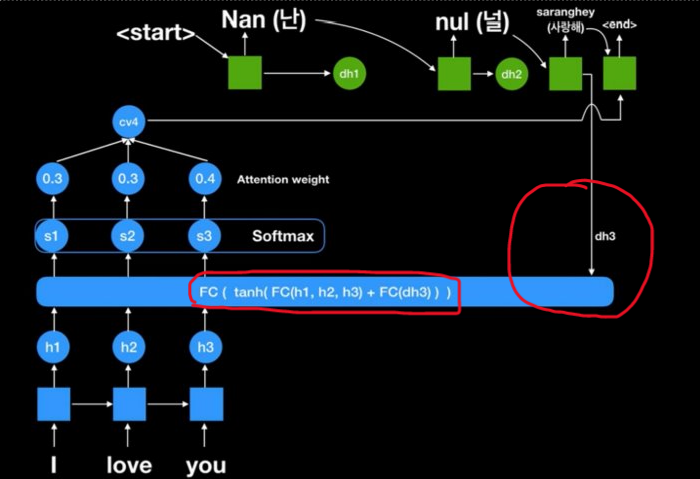
즉, I를 처음에 읽어들여 'Nan'을 출력했다면, Decoder의 Vector도 다시 입력으로 넣어, 다음에 집중해야 할 단어가 'love'보다 'you'임을 알려주게 되는 것이다('난 널 사랑해'이기 때문에). 임의로 표기한 Attention Score이긴 하지만, 위 그림에서 'you'의 Attention이 0.4로 제일 높다. '널'까지 출력했다면 dh3의 입력을 받았을 때, 아마도 S2의 Attention Score가 가장 높게 나타나게 될 것이다. 다르게 도식화하면 아래와 같이, 순차적으로 Context Vector가 변화하는 것을 볼 수 있다.
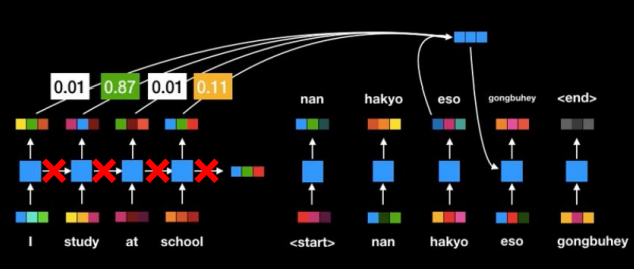
문맥에 따라 Attention Weight이 변하기 때문에 기존 Seq2Seq 모델보다 비약적으로 성능이 향상되었다. 하지만, RNN을 사용하면서 나타나는 연산 속도 저하는 큰 문제가 된다. 이를 해결한 것이 Google의 'Attention is All you need' 논문, 즉, RNN을 없애도 Attention만으로도 충분히 성능을 얻을 수 있는 Self-Attention 모델이다. Self-Attention 모델은 다음에 더...
Attention을 활용한 언어 번역 예제는 아래의 Tensorflow 사이트를 참조하면 된다.
주의를 기울인 신경 기계 번역 | Text | TensorFlow
www.tensorflow.org
무료 Colab으로 약 4~50분 정도의 학습 시간이 소요되는데, 확실히 Seq2Seq 모델만 사용하는 것에 비해 결과가 훌륭하다.
'AI 빅데이터 > 후려치는 데이터분석과 AI 알고리즘' 카테고리의 다른 글
| [자연어분석] BERT, Transformer, Self Attention 후려치기 (1) | 2023.01.28 |
|---|---|
| [데이터보안] LDP ( Local Differential Privacy) (0) | 2023.01.20 |
| [이상탐지] Exponential Smoothing을 활용한 이상탐지 (0) | 2021.02.14 |
| [데이터분석] Feature Engineering 7가지 팁 (0) | 2021.01.11 |
| [데이터분석] 비전을 이용한 식물 분류 (0) | 2020.11.08 |




댓글