솔직히 개념이 좀 와닿지 않아(여전히 그렇다), 계속 피해만 다녔는데 GPT3, ChatGPT의 붐으로 Foundation Model의 근간이 되는 Transformer를 개략적이라도 이해하지 않으면 안될 상황인 듯 해서 아주 브리프하게 후려쳐서 정리해보았다. 대략적인 메카니즘은 이해가 되지만, BERT에서 왜 굳이 Transformer Encoder Layer 위에 FFNN을 쌓고, 그걸 6층으로 다시 만들었는 지 등등의 철학은 여전히 오리무중이다. 하지만, 이제 Transformer 아는 척을 안 하면 밥벌어 먹기 힘든 시대가 결국 온 것 같아서 중심 개념만 정리해 본다.
Transformer를 위해서는 Attention만 보면 되겠지만(오죽하면, 논문 제목도 'Attention is all you need'이겠나!), Transformer의 활용 측면도 보아야 해서 Self-Attention, Transformer, BERT를 살펴 보기로 하자.
Self Attention
Self Attention을 위해서는 우선 Attention을 알아야 하는데...
[자연어분석] Seq2Seq에 Attention 활용하기
RNN 혹은 LSTM과 같은 순차적 모델을 활용해, 언어를 번역하는 것은 아래 포스팅해서 해봤다. [자연어 처리] Seq2Seq 로 자연어 번역하기 언어 처리를 위해서는 시계열성이 반영되는 RNN이나 LSTM, GRU등
magoker.tistory.com
위에서도 살펴 보았지만, RNN 기반 Seq2Seq 모델은 아래의 한계를 갖고 있다.
- 하나의 고정된 벡터에 모든 정보를 압축하려고 하니까 정보 손실이 발생함
- RNN의 고질적 문제 Vanishing Gradient 존재
그래서, 디코딩할 때 인코더의 어느 벡터에 주의(Attention)를 기울일지 알면 도움이 될 것이라며, Attention 개념이 등장했다. 그러면서, 아래의 개념들을 갑자기 들이 밀었는데, 나같은 무지랭이는 '쿼리와 키와 값이 어디야?' 하면서 이해되지 않았다.
- Q = Query : t 시점의 디코더 셀에서의 은닉 상태
- K = Keys : 모든 시점의 인코더 셀의 은닉 상태들
- V = Values : 모든 시점의 인코더 셀의 은닉 상태들
서두에 밝혔듯이 개념만 후려치는 거니까, 이제 Q, K, V는 잊고, 뭔지만 알아보자. 아래 그림에서, 우리 알고 싶은 것은 디코더에 단어가 입력될 때, 인코더의 어느 벡터에 관심을 더 주어야 할지 알고 싶은 것 뿐이다. 즉, t시점에서의 상태(StT)에 인코더에서 LSTM을 통과한 벡터값을 dot product 해 준 것, 그것이 해당 시점에서의 Attention Score가 된다.

여기에 hidden 벡터(h)를 각각 통과해서 나온 값을 softmax한 것이 'Attention Value', 즉, t시점에서는 인코더에 입력된 어느 단어에 더 집중을 해야하는 지가 확률의 형태로 나타난다. 예를 들어 위에서 'suis'의 attention value가 (0.2, 05, 0.1, 0.2)라고 나타났다면, 'am'에 더 관심을 기울이도록 하는 것이다. 이렇게 되면, 문장이 길어져도 RNN의 문제인 Vanishing Gradient 문제를 해결할 수 있다.
여기까지가 Attention인데, 구글의 천재들이 보니까 굳이 RNN을 쓸 필요가 없어보였다. LSTM이 결국 과거 단어들로부터 순차적으로 영향을 받는 것이라면, 그저 문장 내 단어의 위치정보만 있으면 된다고 생각했을 법하다. 게다가, 인코더에서 자신과 동일한 문장으로 학습한다면 문장 내 단어들과의 관계들도 파악할 수 있는데, 이건 LSTM에서는 쉽지 않은 일이었다.

위에서, it이 animal과 street 어느 것을 지칭하는 지 LSTM은 알 수 없었지만, self-attention에서는 animal이라고 파악하게 된 것으로, 문장의 전체 '맥락'을 고려한다는 점에서 언어모델이 진일보하게 되었다.
Transformer
Self-Attention은 2017년 이후 세상을 바꾼 Transformer의 핵심 개념이다.

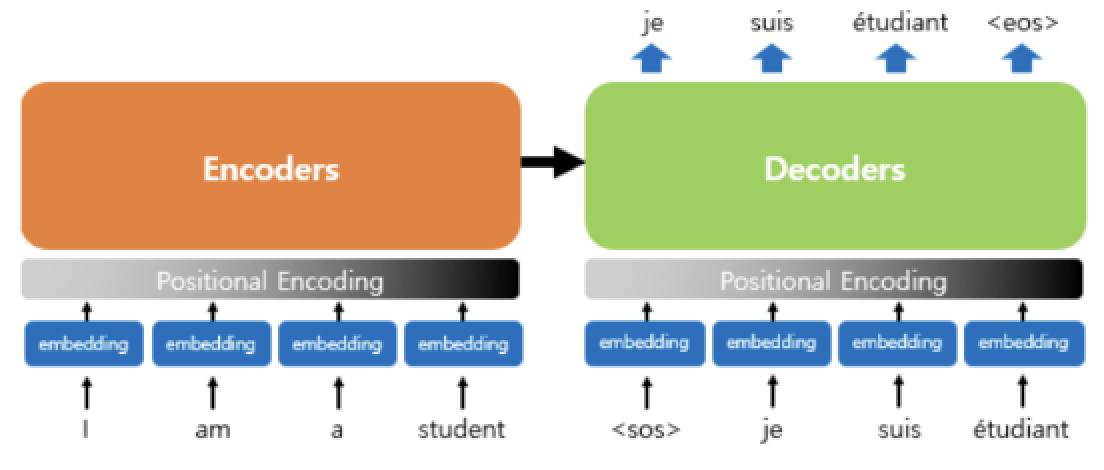
Transformer는 위와 같은 네트워크를 갖고 있는데, 왜 이렇게 구성했는지를 물어본다면 이 포스트의 범위를 넘어선다. 개념만 아는 것이 목적임으로, 간략하게 아래와 같이만 알고 넘어간다.
- LSTM의 순차정보는 Positional Encoding의 위치정보로 대신한다.
- 인코더/디코더의 입력을 스스로 self-attention하여 입력된 단어의 맥락을 파악한다.
- 단, 디코더의 self-attention에서는 과거의 단어들을 참조해야 하므로 관심 이후의 단어를 'mask'한다.
- 디코더의 최종단에서는 디코더 입력과 인코더 입력과의 관심(Attention)을 알아야 하기 때문에, self-attention이 아닌, attention을 사용한다.
참고로, Transformer란 말을 네트워크 구조를 통해서는 전혀 유추할 수 없는데, 저자들은 처음에 'Attention Net'이라고 이름지었다가, '우리는 데이터의 리프리젠테이션(representation)을 바꾸는 transformer라고 생각해'라고 말한데서 그렇게 명명했다고 -__-;;;. 그냥 attention-net이라고 하지...
1) Positional Encoding
LSTM의 순차정보는 이제 없으므로, 임베딩된 단어벡터에 위치 정보를 주파수 형태(sin, cos)로 주는데, 자세한 건 최하단 링크된 문서를 참조한다. 위치정보가 단어마다 존재하므로 입력도 순차적으로 할 필요 없이 한꺼번에 입력을 주어도 된다.
2) Multihead Attention
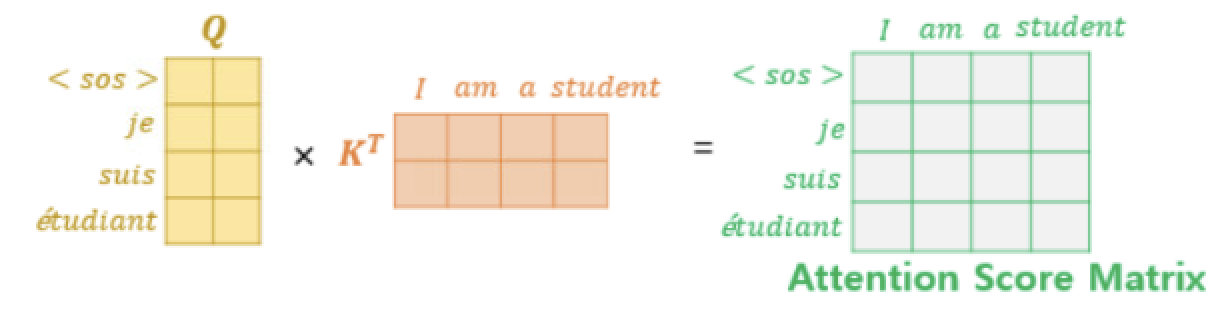
Self-Atttention과 인코더/디코더에서의 활용은 위에서 이야기했으므로, 조금 더 세부적으로 들어가면 Transformer에서는 Multihead Attention이란 개념을 사용한다.

그림과 수식을 이해하려면 여전히 어렵기 때문에, 대략 이렇게만 알고 가자. Transformer에서는 벡터를 나누어 Attention을 병렬로 수행한다. 위에서 예시를 둔 문장 'The animal didn't crossed the street because it is tired'에서는 it이 animal이지만, 관점(헤드)에 따라서는 street나 tired에 더 높은 연관들을 보일 수 있어 이런 내용들을 여러 각도로 보고 판단을 내릴 수 있게 해 준다고 한다. 라고 문서들이 설명하지만 이해가 안될 것이다. 나도 안된다. 좀 찾아(https://stackoverflow.com/questions/66244123/why-use-multi-headed-attention-in-transformers)보면, Attention이 RNN보다 설명력이 좀 약한데, 멀티헤드를 사용하면 앞뒤 단어를 더 참고한다든지 하는 설명력을 높일 수 있지만, 그 과정이 인간이 이해(Human Interpretable)한다고 보장은 안한다는 말도 있다. 일단, 좀 더 잘 맞춰보려고 쓴다라고만 이해합시다.
3) Look Ahead Mask
위에서 디코더의 self attention은 인코더의 그것과 다르다고 이야기했는데, 디코더에서는 단어가 순차적으로 입력되고, 어떤 단어로 나타낼 것인지 맞춰야 하는 것이므로, 디코더 입력의 이후 입력들을 참조해서는 안된다.

따라서, 위와 같이 아직 참조하면 안되는 단어들은 마스킹 처리해서 사용하게 된다.
4) 인코더-디코더 Attention
마지막 단계로 인코더-디코더를 엮어주어야 하는데, LSTM에 Attention을 주었던 과정과 유사하게 생각하면 된다. 단, 여기서도 멀티 헤드 어텐션이 사용된다.
네트워크 각 레이어를 엮을 때, Vision(ResNet 등)에서 많이 사용되는 Residual Connection과 정규화(Normalization)가 사용되는 정도까지만 이야기하고 Transformer는 마무리. 여러 테크닉들을 이야기했지만, 핵심은 RNN의 순차 정보를 없애고, 위치 정보와 문장 내 혹은 문장 간의 단어들의 연관성으로 맥락을 이해하는 모델 정도로만 이해한다.
BERT
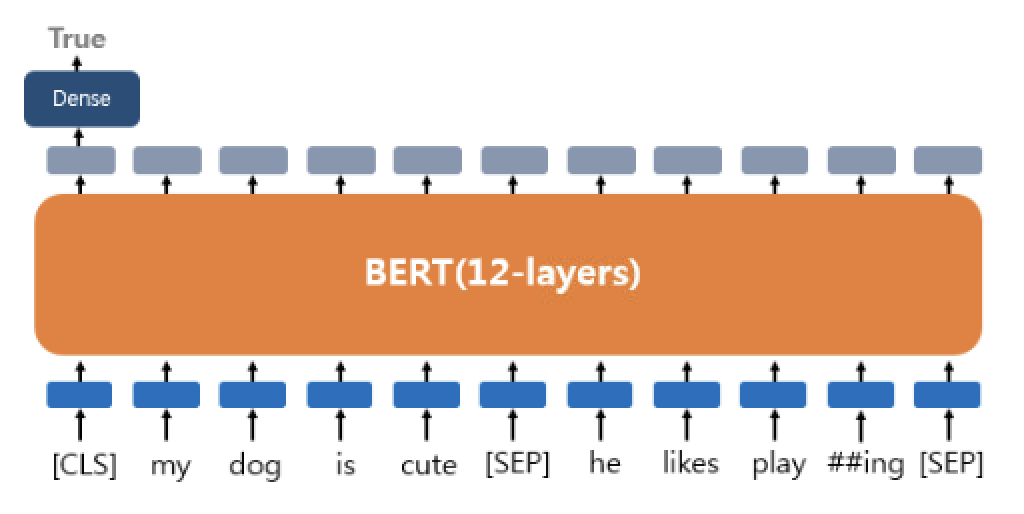
Transformer는 GPT와 BERT 등 초거대AI 모델의 기본이 된다. 여기서는 BERT의 네트워크 구조를 자세히 살펴보기보다는 핵심적인 아이디어 두가지(Masked Language Model, Next Sentence Prediction)와 활용 측면에서만 볼 것이다.
1) Masked Language Model

GPT가 '생성'에 초점을 맞추고 단방향으로 네트워크를 구성했다면, BERT는 벡터간의 양방향성을 갖고 '이해'에도 초점을 맞추고 있다. 이렇게 되면, Transformer에서 나타났던, '이후 단어 참조'의 문제가 나타나게 된다. 그래서 MLM(Masked Language Model)이 고안되었다.

언어모델이 무조건 다음 단어 매칭을 하는 것이 아니라, 맥락상 어떤 말이 들어가는 것이 맞나만을 판별하면 되기 때문에, BERT에서는 입력 문장의 일부(15%)를 Masking처리하고, 어떤 단어가 들어가는 것이 맞을 지 '지도학습'하게 된다. 정확하게는 10%는 마스킹하고, 2.5%는 일부러 틀린 입력을 넣으며, 2.5%는 맞는 입력이지만 맞는 단어인지 모르는 상태에서 학습한다.
2) Next Sentence Prediction
BERT의 두번째 특징인 NSP(Next Sentence Prediction)이다.

말그대로 다음 문장을 예측하는 것으로, [SEP]이라는 토큰으로 구분된 두 문장의 연속성을 판단하도록 classifier를 두고 학습하는 것이다.
- 이어지는 문장의 경우 (Label = IsNextSentence)
Sentence A : The man went to the store.
Sentence B : He bought a gallon of milk.
- 이어지는 문장이 아닌 경우 경우 (Label = NotNextSentence )
Sentence A : The man went to the store.
Sentence B : dogs are so cute.
NSP는 BERT가 Q&A에서 활용될 수 있도록 고안되었다.
3) BERT Fine Tuning
BERT 모델은 학습데이터를 추가로 넣고 Fine Tuning하면 용도에 맞게 모델을 재활용할 수 있도록 고안되었다. 활용 예는 아래를 참조한다.
| Text Classification | Tagging |
 |
 |
| Text Pair Classification or Regression | Q&A |
 |
 |
많은 내용을 너무 간략히, 그것도 충분한 이해도 없이 정리하려니 틀린 부분이 있을까 우려된다. BERT, Transformer 관련해서는 엄청나게 많은 블로그 포스팅과 문서들이 있지만, 아래 위키독스 페이지가 제일 쉽게 설명되어 있는 듯하다. 간단한 구현도 포함되어 있다.
참조 링크
어텐션: https://wikidocs.net/22893
트랜스포머: https://wikidocs.net/31379
'AI 빅데이터 > 후려치는 데이터분석과 AI 알고리즘' 카테고리의 다른 글
| [Basic] Step-by-Step 분류 Python 예제 (0) | 2024.02.02 |
|---|---|
| [데이터보안] LDP ( Local Differential Privacy) (0) | 2023.01.20 |
| [자연어분석] Seq2Seq에 Attention 활용하기 (0) | 2021.11.30 |
| [이상탐지] Exponential Smoothing을 활용한 이상탐지 (0) | 2021.02.14 |
| [데이터분석] Feature Engineering 7가지 팁 (0) | 2021.01.11 |




댓글