비전 기술은 불량을 찾아내기 위한 공정 검사에 많이 쓰인다. 비전 기술을 쉽게 따라하기 위해 Kaggle의 식물 분류 과제를 잘 정리한 노트북을 따라 실습해 보았다.
Plant Seedlings Classification
Determine the species of a seedling from an image
www.kaggle.com
과제는 주어진 학습데이터를 12종의 식물분류로 학습하고 테스트 이미지 데이터가 어떤 식물인지 맞추는 것이다. MNIST의 이미지 인식 버전이고 식물 종류가 좀 더 많아졌다고 생각하면 된다. 참조한 노트북은 아래와 같이 잘 정리되어 있다.
Plant Seedlings with CNN and Image Processing
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
짧지만 필요한 요소들을 잘 정리하고 있다. 아래는 Train 이미지를 읽어들여서 Image Array와 Label을 분리하는 것을 보여준다.
import cv2
from glob import glob
import numpy as np
from matplotlib import pyplot as plt
import math
import pandas as pd
# 이지미를 70x70으로 Resize
ScaleTo = 70
seed = 7
path = './train/*/*.png'
files = glob(path)
trainImg = []
trainLabel = []
j = 1
num = len(files)
for img in files:
print(str(j) + "/" + str(num), end="\r")
trainImg.append(cv2.resize(cv2.imread(img), (ScaleTo, ScaleTo)))
trainLabel.append(img.split('/')[-2])
j+=1
trainImg = np.asarray(trainImg)
trainLabel = pd.DataFrame(trainLabel)
for i in range(8):
plt.subplot(2, 4, i+1)
plt.imshow(trainImg[i])
cv2는 이미지 처리를 위한 opencv를 활용하기 위한 라이브러리다. 이미지는 70x70으로 통일한다.

잎의 이미지만 있으면, CNN으로 패턴만 비교하여 분류하면 되지만, 잎의 색도 고르지 않고 무엇보다 배경 이미지가 있어 학습이 잘되지 않을 수 있다. 잎은 대부분(!) 녹색이므로 대체로 녹색이라고 인지될 수 있는 부분만 타원(eclipse)의 합 형태로 가져올 수 있도록 전처리 해 본다.
clearTrainImg = []
examples = []
getEx=True
# 녹색의 범위
lower_green = (25, 40, 50)
upper_green = (75, 255, 255)
for img in trainImg:
#RGB보다는 HSV가 색 Filtering하기 용이
hsvImg = cv2.cvtColor(cv2.GaussianBlur(img, (5, 5), 0), cv2.COLOR_BGR2HSV)
# 색 필터링
mask = cv2.inRange(hsvImg, lower_green, upper_green)
# 타원 모양으로 11x11 매트릭스를 형성
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (11, 11))
mask = cv2.morphologyEx(mask, cv2.MORPH_CLOSE, kernel)
# Mask
bmask = mask > 0
clear = np.zeros_like(img, np.uint8)
# 원본에서 mask가 있는 영역만 따로 가져옴
clear[bmask] = img[bmask]
clearTrainImg.append(clear)
if getEx:
plt.subplot(2, 3, 1); plt.imshow(img) # Show the original image
plt.subplot(2, 3, 3); plt.imshow(hsvImg) # HSV image
plt.subplot(2, 3, 4); plt.imshow(mask) # Mask
plt.subplot(2, 3, 5); plt.imshow(bmask) # Boolean mask
plt.subplot(2, 3, 6); plt.imshow(clear) # Image without background
getEx = False
코드에도 주석을 달았지만, 녹색 계열의 픽셀만 필터링해서 마스크를 만들고 마스크가 true인 픽셀만 원본에서 가져오는 것이다.
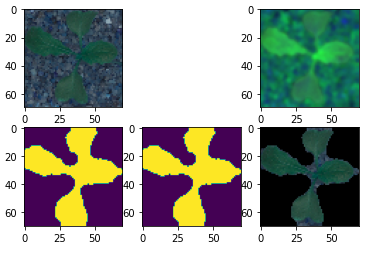
테스트한 첫번째 이미지는 잎 모양만 비교적 잘 오려서 가져왔다. 이제 잎모양만 가져왔으므로 적절한 이미지 학습 네트워크에 분류 값과 넣어 학습하면 된다. 주의할 점은 Train 데이터를 있는 그대로만 활용하면 모양이 비틀어지거나 하는 테스트 세트에서는 결과가 좋아지지 않을 수 있다. 그래서, 임의로 조작한 이미지 데이터도 같이 학습을 해 주게 된다.
# 학습데이터 정규화
clearTrainImg = clearTrainImg / 255
from keras.utils import np_utils
from sklearn import preprocessing
import matplotlib.pyplot as plt
# 학습 레이블을 카테고리화
le = preprocessing.LabelEncoder()
le.fit(trainLabel[0])
encodeTrainLabels = le.transform(trainLabel[0])
num_clases = clearTrainLabel.shape[1]
trainLabel[0].value_counts().plot(kind='bar')

from sklearn.model_selection import train_test_split
trainX, testX, trainY, testY = train_test_split(clearTrainImg, clearTrainLabel,
test_size=0.1, random_state=seed,
stratify = clearTrainLabel)
# 이미지 학습 데이터를 부풀린다. 자세한 설명은 아래 URL 참조
# https://tykimos.github.io/2017/06/10/CNN_Data_Augmentation/
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=180, # randomly rotate images in the range
zoom_range = 0.1, # Randomly zoom image
width_shift_range=0.1, # randomly shift images horizontally
height_shift_range=0.1, # randomly shift images vertically
horizontal_flip=True, # randomly flip images horizontally
vertical_flip=True # randomly flip images vertically
)
datagen.fit(trainX)
import numpy
import tensorflow as tf
numpy.random.seed(seed) # Fix seed
model = tf.keras.models.Sequential()
# 필터를 64 -> 128 -> 256 개로 늘려가며 CNN 층을 쌓아감
model.add(tf.keras.layers.Conv2D(filters=64, kernel_size=(5, 5), input_shape=(ScaleTo, ScaleTo, 3), activation='relu'))
model.add(tf.keras.layers.BatchNormalization(axis=3))
model.add(tf.keras.layers.Conv2D(filters=64, kernel_size=(5, 5), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
model.add(tf.keras.layers.BatchNormalization(axis=3))
model.add(tf.keras.layers.Dropout(0.1))
model.add(tf.keras.layers.Conv2D(filters=128, kernel_size=(5, 5), activation='relu'))
model.add(tf.keras.layers.BatchNormalization(axis=3))
model.add(tf.keras.layers.Conv2D(filters=128, kernel_size=(5, 5), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
model.add(tf.keras.layers.BatchNormalization(axis=3))
model.add(tf.keras.layers.Dropout(0.1))
model.add(tf.keras.layers.Conv2D(filters=256, kernel_size=(5, 5), activation='relu'))
model.add(tf.keras.layers.BatchNormalization(axis=3))
model.add(tf.keras.layers.Conv2D(filters=256, kernel_size=(5, 5), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
model.add(tf.keras.layers.BatchNormalization(axis=3))
model.add(tf.keras.layers.Dropout(0.1))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(256, activation='relu'))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(256, activation='relu'))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(num_clases, activation='softmax'))
model.summary()
# compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit model
# 학습에서 fit이 아닌 fit_generator로 ImageDataGenerator에서 생성된 데이터도 학습
hist = model.fit_generator(datagen.flow(trainX, trainY, batch_size=75),
epochs=10, validation_data=(testX, testY),
steps_per_epoch=trainX.shape[0])
차이점은 마지막 학습할 때 fit이 아닌 fit_generator를 통해 부풀리기 된 이미지도 학습한다는 정도다.
아래의 코드를 통해 evaluate 해 보자. 일부 오류도 있지만 대체로 잘 맞추는 듯 하다.
from sklearn.metrics import confusion_matrix
predY = model.predict(testX)
predYClasses = np.argmax(predY, axis=1)
trueY = np.argmax(testY, axis = 1)
confusion_matrix(trueY, predYClasses)

마지막으로 Test 데이터를 불러와서 테스트하는 부분은 아래와 같다. Kaggle에 제출할 것이 아니라면 위의 내용정도로 충분하다. 다른 것은 없고 Train 데이터 대신 Test 데이터를 마스크 만들어 전처리하고 모델에서 Predict하는 것이다.
path = 'test/*.png'
files = glob(path)
testImg = []
testId = []
j = 1
num = len(files)
# Obtain images and resizing, obtain labels
for img in files:
print("Obtain images: " + str(j) + "/" + str(num), end='\r')
testId.append(img.split('/')[-1]) # Images id's
testImg.append(cv2.resize(cv2.imread(img), (ScaleTo, ScaleTo)))
j += 1
testImg = np.asarray(testImg) # Train images set
clearTestImg = []
examples = []; getEx = True
for img in testImg:
# Use gaussian blur
blurImg = cv2.GaussianBlur(img, (5, 5), 0)
# Convert to HSV image
hsvImg = cv2.cvtColor(blurImg, cv2.COLOR_BGR2HSV)
# Create mask (parameters - green color range)
lower_green = (25, 40, 50)
upper_green = (75, 255, 255)
mask = cv2.inRange(hsvImg, lower_green, upper_green)
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (11, 11))
mask = cv2.morphologyEx(mask, cv2.MORPH_CLOSE, kernel)
# Create bool mask
bMask = mask > 0
# Apply the mask
clear = np.zeros_like(img, np.uint8) # Create empty image
clear[bMask] = img[bMask] # Apply boolean mask to the origin image
clearTestImg.append(clear) # Append image without backgroung
clearTestImg = np.asarray(clearTestImg)
clearTestImg = clearTestImg / 255
pred = model.predict(clearTestImg)
predNum = np.argmax(pred, axis=1)
predStr = le.classes_[predNum]
res = pd.DataFrame({'file': testId, 'species': predStr})
res.to_csv("res.csv", index=False)
간단히 처리했는데 약 86.7 퍼센트의 정확도로 예측하였다. 이미지를 기계가 읽어 판별하는데 위처럼 간단한 코드로 얻은 성적치고는 나쁘지 않다. 다만, 일반적 비전 환경에서는 공정데이터와 같이 불량의 데이터가 상당히 적어 학습이 어렵거나, 사람이 실수하여 레이블링을 잘못 해 학습결과가 나쁜 경우가 상당히 빈번하다. 비전에서는 학습 네트워크 못지 않게 이에 대한 연구가 많이 이루어지고 있다.
'AI 빅데이터 > 후려치는 데이터분석과 AI 알고리즘' 카테고리의 다른 글
| [이상탐지] Exponential Smoothing을 활용한 이상탐지 (0) | 2021.02.14 |
|---|---|
| [데이터분석] Feature Engineering 7가지 팁 (0) | 2021.01.11 |
| [데이터분석] Anomaly Detection을 위한 데이터 탐색 (0) | 2020.11.01 |
| [데이터분석] 주택가격 예측 Kaggle 도전기 (0) | 2020.09.25 |
| [데이터분석] GAN으로 수치 데이터 생성하기 (2) | 2020.09.17 |




댓글