최근 페이스북 포스팅에서 AI반도체의 방향에 관한 논쟁(?)을 접했다. 국가 단위로 투자한다면서 기껏(?) 인퍼런스 칩 만드는 업체들 불러다 놓았냐라는 얘기가 있었나보다. 초거대AI로 시장이 발전하고 있으니 대량학습이 가능한 훈련용 칩과 데이터 대역폭을 개선할 NoC(네트워크 반도체)에 역량을 집중해야 한다는... OpenAI나 구글과 싸우려면 그 방향이 맞겠지만, 개인적으로는 이제 그 쪽 승부는 이미 났고 추론을 얼마나 빨리 잘할 수 있느냐가 미국을 제외한 국가들에서 관심가져야 할 분야인 듯 싶다. 혹은 학습을 위해서도 새로운 칩 만드는데 투자하기 보다는 그 돈으로 구글이나 NVidia, 혹은 클라우드 업체의 인프라를 사용하는 것도 방법이다. 하지만, 인퍼런스 분야는 다르다. 지금이야 AI용처가 한정되지만, 초거대AI 기반으로 지천에 서비스가 깔리면, 사용만큼 비용이 발생하고 서비스 범위도 엄청나게 다양해지기 때문에 Lease해서는 경쟁 우위를 가져가기 힘들게 될 것이다.
이런 얘기하려고 했던 것은 아니고.. 다시 본론으로 돌아오자면, NVidia가 학습용칩은 꽉잡고 있지만, 초거대AI로 학습한 간단한 모델을 추론하는 데에도 A100 머신 정도는 가뿐이 필요하다. 전기도 많이 먹고 하나에 1억이나 하는 칩을 곳곳에 깔 수는 없고, 이미 모바일에서 많이 쓰이고 있는 NPU(Neural Processing Unit)이 버티컬 별로 많이 나올 듯 하다.
NPU (Neural Processing Unit)
아래 그림은 삼프로tv에서 리벨리온 박성현 대표가 NPU의 발전 방향을 소개하는 것을 가져왔다. 대표적 NPU인 Google TPU는 추론 전용칩이었지만, 점점 학습을 위해 개량되었다. NPU의 큰 형님격인 삼바노바나 그래프코어 같은 경우도 하드웨어 비효율을 감수하면서 새로운 알고리즘에 더 잘 대응할 수 있도록 방향성을 잡았다. 그렇다면 GPU랑 무슨 차이가...

리벨리온은 다시 NPU의 초심으로 돌아가자며 유연성은 일부 희생하더라도 하드웨어 효율을 높이는 방향성을 갖고 있다. 구글도 마찬가지. TPU v4에서는 학습용과 추론용(v4i) 칩을 별도로 출시한다.
그럼 NPU는 GPU와 어떻게 다른가! 구글 TPU 소개 페이지에 잘 설명되어 있다.
우선 CPU부터 보면, 데이터를 메모리에 하나 올려 놓고 연산한 결과를 다시 메모리로 출력한다. 메모리에 연산에 필요한 데이터를 올려 놓고 CPU는 필요한 연산을 자유롭게 가져갈 수 있으니 유연성은 엄청나게 높아지지만, 메모리 액세스 속도가 연산 속도에 비해 엄청나게 느리므로 CPU는 노는 일이 많아진다.

GPU는 그래픽 처리와 같이 동일한 연산을 반복적으로 많이 처리해야 하는 경우에 유용하다. 산술계산유닛(ALU: Arithmatic Logical Unit)코어를 2천~5천개씩 두고 데이터를 흘려보내면 병렬적으로 처리한다. 행렬연산이 많은 딥러닝 학습에서 GPU가 중요한 이유가 여기에 있다. 다만, AMD가 아닌 NVidia가 딥러닝 학습 시장을 다 먹은 건, CUDA(Compute Unified Device Architecture)에 기반한 딥러닝 소프트웨어 스택 덕분이다. 새로운 GPU 혹은 NPU가 나오더라도 CUDA를 고려하지 않으면 시장 진입이 어려울 수 있다.

GPU도 레지스터라는 내부 메모리를 사용하기 때문에 CPU보다는 낫지만 여전히 병목의 문제가 있다. 구글은 딥러닝이 텐서 연산이라는 제한된 영역에서 사용되므로, 범용적 산술연산은 포기하는 대신 딥러닝에 필요한 부분만 남긴 NPU(TPU)를 출시한다. 각 행렬 연산의 결과가 메모리를 거치지 않고 다음 누산기로 바로 이동하게 되므로 병목을 해결하게 된 것이다.
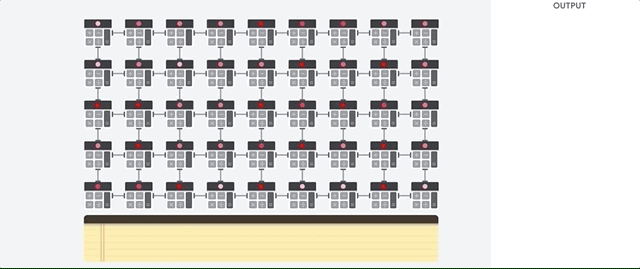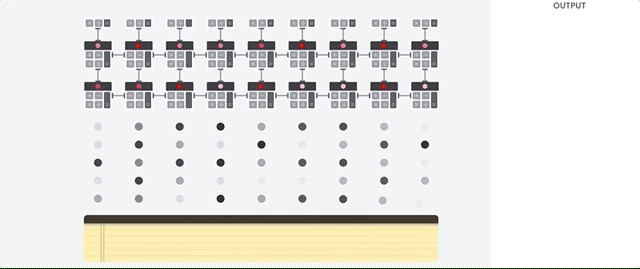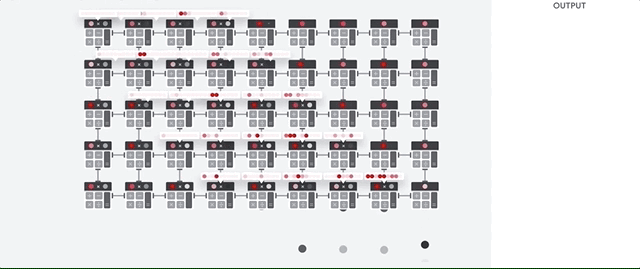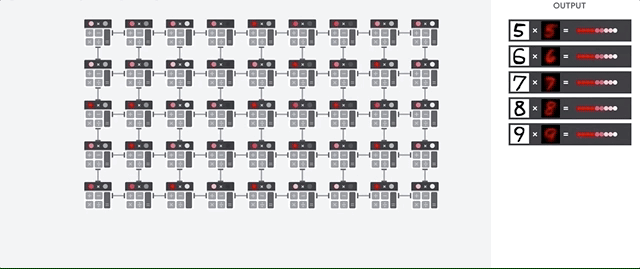
딥러닝에는 좋은 결과를 가져오지만, 메모리 유닛이 없고 연산방식이 고정되어 있으므로 분기 처리가 필요하거나 요소별로 다른 연산이 필요한 경우에는 사용이 어렵다. 초기에는 INT4 형태로 데이터를 양자화해서 사용하여 고정밀 연산도 불가능했으나, 최근에는 FP16을 지원하고 있다고 한다.
TPU는 CGRA(Coarse-Grained Reconfigurable Architecture)에서와 같이 유연성을 높여 알고리즘의 Future Proof가 가능하지만, 아래서와 같이 비싼 반도체가 많이 놀게 되는 현상이 벌어진다.

리벨리온 아이온의 경우, 레이턴시가 중요한 금융 분야 특화된 AI반도체를 만들겠다는 목표로 비용과 성능 최적화를 하고 있다. 최근에는 범용성이 필요한 서버용 시장에 진출했지만, 어느 정도의 성능차이를 가져올 지는 아직 궁금하다. 다른 국내 AI반도체 업체 사피온과 퓨리오사는 NVidia A2, T4 등 구형 혹은 활용이 제한된 GPU와 비교하고 있어, 초거대AI 시장에서 얼마나 힘을 쓸지는 의문이다.
'AI 빅데이터 > AI 동향' 카테고리의 다른 글
| [GPT-3] GPT-3 FineTuning 하기 (0) | 2023.02.19 |
|---|---|
| [하드웨어] NVSwitch, 인피니밴드, PIM, PNM (0) | 2023.01.29 |
| [Google] Jeff Dean - 2022년 Google AI의 성과 요약 (0) | 2023.01.24 |
| [초거대 AI] Anthropic AI Claude (0) | 2023.01.12 |
| Coatue의 AI2022: The Explosion (0) | 2023.01.09 |




댓글