초거대AI가 주목받고 100B 이상의 파라미터 사용이 특이한 일이 아니면서부터 딥러닝학습을 위한 하드웨어에도 많은 관심이 쏟아진다. 무엇보다 시스템 반도체업체인 NVidia의 인프라는 SUPERPOD이라는 이름으로 수십, 수백의 GPU를 묶는 형태로 발전하고 있다. 반면, 메모리 반도체 영역에서도 메모리에 연산기능을 추가하면서 초거대 AI에 대응하고 있다.
시스템 반도체 업체의 대응
시스템반도체 업체라고 해봐야 NVidia를 말하는 것일텐데, NVidia는 A100, H100으로 반도체 성능을 높이는 한편, 이들을 네트워크로 묶어 SUPERPOD의 형태로 제공하고 있다. SUPERPOD은 NVSwitch와 인피니밴드 연결로 구분될 수 있다.

위는 NVSwitch의 구조를 나타내고 있는데, CPU(AMD Rome)와는 PCI-E로 연결되어 있는 반면에 GPU들은 느린 PCI를 거치지 않고 NVSwitch에 NVLink로 물려 있음을 볼 수 있다. 최신 칩인 H100의 경우 NVSwitch 하나 당 8개의 GPU가 연결될 수 있고, 서버간 연결까지 고려하면 무려 256개의 GPU를 900GB/s의 속도로 연결할 수 있다.
NVSwitch로 묶인 클러스터들 간에도 Infiniband 기술로 확장 가능하다. 인피니밴드는 2000년에 나온 표준으로 공유 구조인 PCI의 한계나 6개의 프로토콜 레이어를 거쳐야 하는 이더넷의 한계를 해결하기 위해 등장했다. 여기에 또 RDMA(Remote Direct Memory Access)라는 기술 기반하에서 CPU의 간섭을 최소로하여 성능 향상을 이끌어 낸다. 과거에는 GPU 통신을 위해 CPU 메모리로 데이터를 옮기고, 인피니밴드를 통해 다른 시스템의 CPU메모로 복사한 후, 다시 GPU메모리로 데이터를 복사하여 병렬 수행해야만 했다. NVidia는 RDMA 기술로 CPU간섭을 벗어난 것 뿐 아니라, GPU끼리 바로 통신할 수 있는 GPUDirect라는 기술까지 적용하고 있다.


이와 같이 NVidia가 Scale-out을 통해 대량 학습에 대응하고 있다면, 메모리반도체업체(삼성, 하이닉스)들은 메모리에 연산장치를 넣는 방식을 제공한다.
메모리 반도체 업체의 대응
메모리 반도체 업체는 GPU-메모리간 통신을 줄이기 위해 일부 연산을 메모리에서 바로 수행 가능하도록 PIM(Processing-in-Memory) 을 제공한다. GDDR보다 대역이 향상된 표준인 HBM(High Bandwidth Memory)와 함께 사용되기 때문에 통상 HBM-PIM 기술이라고 부른다.

위의 그림에서와 같이 일부 로직 유닛을 메모리에 담아 연산된 결과를 GPU에 돌려주기 때문에, 2배 이상의 성능향상과 70% 이상의 에너지 소비 감소가 있다고 주장한다. 다만, 메모리칩에 산술로직 유닛까지 탑재하다보니 가격이 많이 비싸진다. 그래서인지 NVidia가 아닌 AMD MI-100 칩과 협력하고 있다. MI-100의 연산 능력 자체는 A100 이상인 것으로 알려지고 있으나, CUDA를 제공하고 있지 않아 범용적으로 사용되기에는 아직 무리가 있다.
이런 가격 이슈를 최대한 줄여보고자 하는 시도가 PNM(Processing Near Memory) 기술이다. 메모리 다이 내가 아닌 메모리 패키지에 산술 유닛을 탑재하는데, 통신속도와 대역폭을 높이기 위해 TSV(Through Silicon Via) 공법을 사용하고 있다.
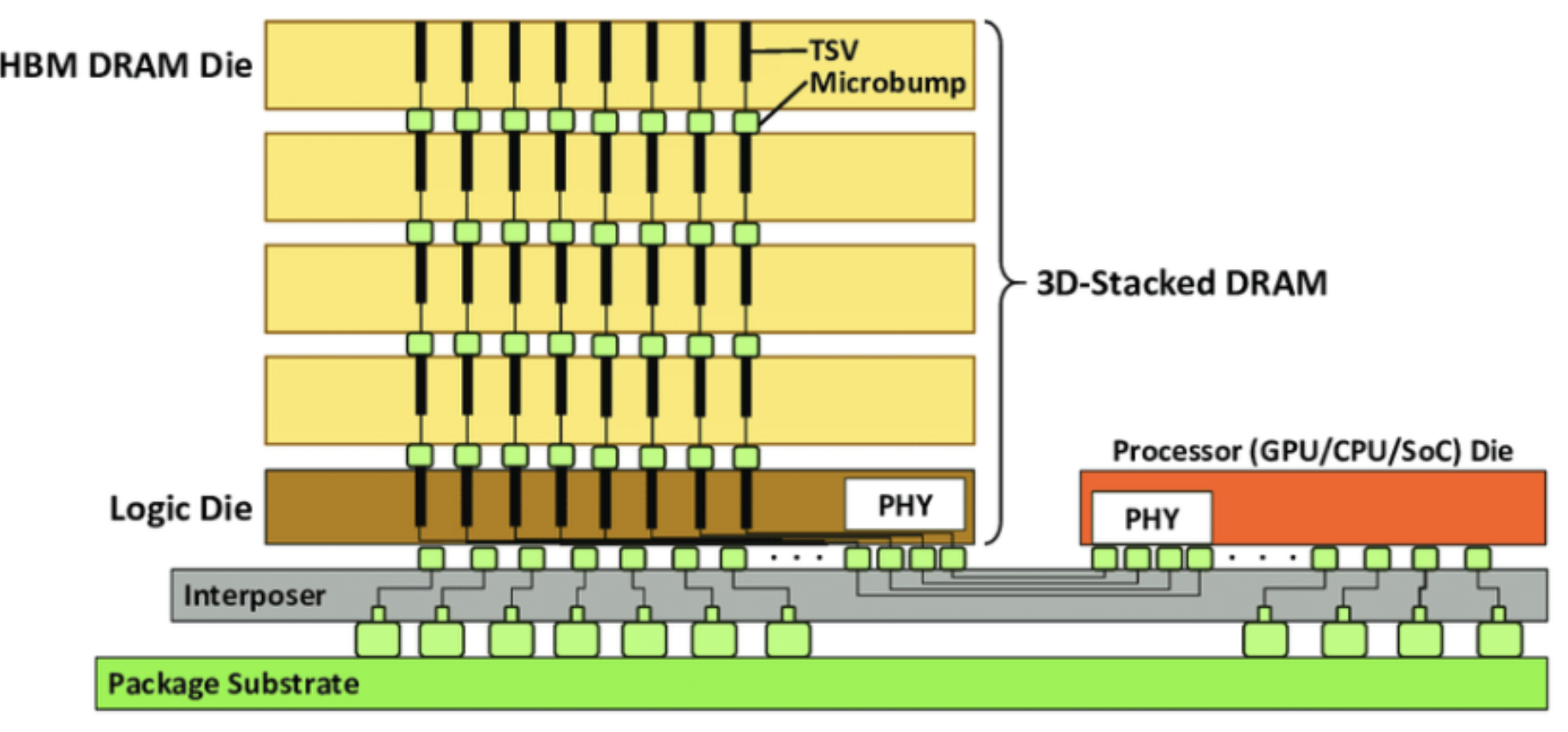
상대적으로 난이도가 낮지만, 아무튼 인터페이스를 거쳐야 해서 PIM만큼의 성능향상을 기대하기는 어렵다. 메모리 업체에서 사용하는 또 하나의 기술은 CXL(Compute Express Link)로, 시스템의 물리적 메모리를 획기적으로 늘리기 위한 기술이다.

딥러닝 학습을 하다보면 메모리 부족으로 학습이 중지되는 경우가 다반사인데, 대용량 데이터를 처리하는 데 도움을 줄 수 있을 듯하다. 삼성전자는 위의 세가지 기술로 네이버의 하이퍼스케일AI 협력을 하고 있다.
메모리 업체는 스케일 아웃하기는 쉽지 않지만(CXL로 다른 GPU와 공유메모리를 설정하여 일부 가능), 일부 연산 기능을 대신한다거나 용량을 늘려서 딥러닝 학습 향상을 대응하고 있다.
'AI 빅데이터 > AI 동향' 카테고리의 다른 글
| [LLaMa] M1 Mac에 Meta LLaMa 동작시키기 (0) | 2023.03.14 |
|---|---|
| [GPT-3] GPT-3 FineTuning 하기 (0) | 2023.02.19 |
| [하드웨어] AI를 위한 반도체 NPU 후려치기 (2) | 2023.01.29 |
| [Google] Jeff Dean - 2022년 Google AI의 성과 요약 (0) | 2023.01.24 |
| [초거대 AI] Anthropic AI Claude (0) | 2023.01.12 |




댓글