시계열 분석을 하는 데 있어 전통적 방법인 ARIMA와 최근에 많이 이용되는 XGBoost를 활용하는 방법을 보았다. 아래 ARIMA 포스팅의 Kaggle Data를 사용한다.
[데이터분석] 시계열 분석 - ARIMA
기업 내 데이터분석이 많아지면서 자연스럽게 시계열분석에 대한 Needs가 많아졌다. 마케팅/구매/SCM 등 가치 사슬 내 거의 모든 부분이 시계열 데이터에 의존하고 있는데, 기존의 통계적 접근에��
magoker.tistory.com
[데이터분석] 시계열분석 - XGBoost
이전 포스팅에서는 상점 매출 데이터를 ARIMA로 분석하여 예측하는 것을 해 보았다. [데이터분석] 시계열 분석 - ARIMA 기업 내 데이터분석이 많아지면서 자연스럽게 시계열분석에 대한 Needs가 많아
magoker.tistory.com
시계열 분석의 마지막 방법으로 딥러닝을 활용한 방법을 보고자 한다. 시간성을 갖고 있으므로 RNN계열의 LSTM을 활용하는데, 코드는 XGBoost 활용 시와 유사하고 학습하는 것만 약간 다르다.
1) 전처리
XGBoost 사용 시와 대부분의 전처리는 유사하고, 마지막 부분의 LSTM Input Dimension 형태로 변환해 주는 것만 유의하면 된다. LSTM의 입력은 3차원으로 (samples 수, time step 수, feature 수)인데, time step 수는 하나의 데이터에 들어가는 칼럼 수, feature 수는 몇 개의 low를 한번에 입력할 것인가 정도로 이해하면 편하다. 여기서는 5개의 column (year, month, dayofweek, store, item)을 활용하므로 (전체 samples, 5, 1)이 된다. (생각해보니 월별로 판매를 합계냈으니, dayofweek은 제외해도 될뻔.. 귀찮아서 다시 돌리지는 않을 예정)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime
df = pd.read_csv("data/train.csv")
df['date'] = pd.to_datetime(df['date'])
df = df.set_index('date')
# store와 item 별로 그룹을 나누고 판매량을 월별로 합산하여 전처리
df = df.groupby(['store', 'item'])['sales'].resample('M').sum()
df = df.reset_index()
df = df.set_index('date')
df['month'] = df.index.month
df['year'] = df.index.year
df['dayofweek'] = df.index.dayofweek
split = "2017-01-01"
df_train = df[:split]
df_test = df[split:]
# Y값은 판매량, 나머지 항목들로 X값을 구성
df_train_y = df_train.loc[:,'sales']
df_train_x = df_train.drop('sales', axis=1)
df_test_y = df_test.loc[:,'sales']
df_test_x = df_test.drop('sales', axis=1)
df_test_orig = df_test.loc[:, ['store', 'item', 'sales']]
# LSTM 학습을 위해 3차원 배열로 X값을 변형
train_x = np.array(df_train_x).reshape(df_train_x.shape[0], df_train_x.shape[1], 1)
test_x = np.array(df_test_x).reshape(df_test_x.shape[0], df_test_x.shape[1], 1)
2) 학습
학습은 위에서 전처리 된 데이터를 그대로 LSTM 함수 안에 넣어주면 끝.
import keras
from keras.layers import Dense
from keras.models import Sequential
from keras.utils import to_categorical
from keras.optimizers import SGD,Adadelta,Adam,RMSprop
from keras.callbacks import EarlyStopping
from keras.utils import np_utils
import itertools
from keras.layers import LSTM
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
from keras.layers import Dropout
# input shape에 전처리된 train_x의 형태를 넣는다
# 20%로 Drop-out 했다
model = keras.Sequential()
model.add(keras.layers.LSTM(units=128,input_shape=(train_x.shape[1], train_x.shape[2])))
model.add(keras.layers.Dropout(rate=0.2))
model.add(keras.layers.Dense(units=1))
model.compile(loss='mean_squared_error', optimizer='adam')
# 10개의 batch로 100번 epoch 함
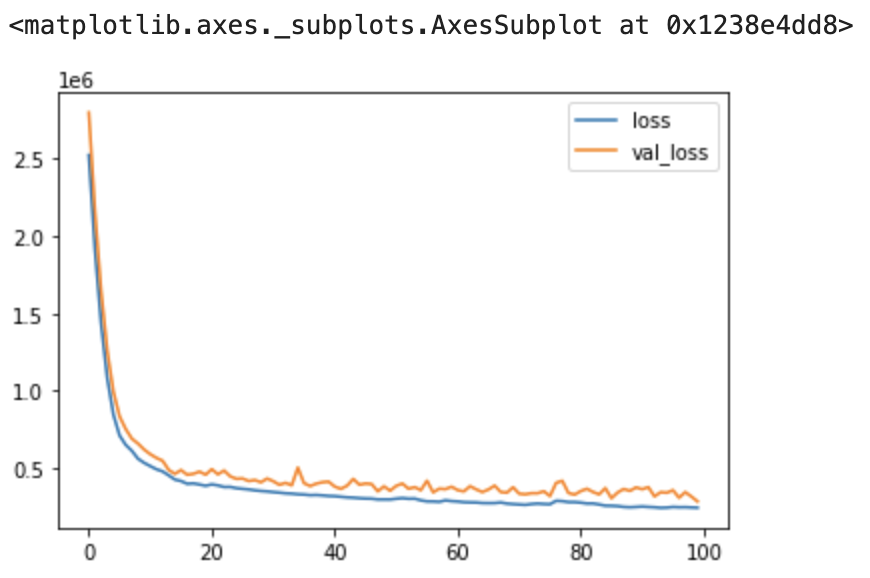
history = model.fit(train_x, df_train_y, validation_split=0.1, batch_size=10, epochs=100)
pd.DataFrame.from_dict(history.history).plot()
학습은 제법 잘된다. 학습은 학습일뿐
3) 테스트
마련해 두었던 2017년 데이터에서 store와 item을 지정해서 test 해 본다.
df1 = df_test_x[(df_test_x.store==3) & (df_test_x.item==2)]
test_x = np.array(df1).reshape(df1.shape[0], df1.shape[1], 1)
result = model.predict(test_x)
# 그래프로 비교해 보기 위해 결과를 Original Data에 붙임
result_df=pd.concat([df_test_orig[(df_test_orig.store==3)&(df_test_orig.item==2)].reset_index(),
pd.DataFrame(result, columns=['lstm'])], axis=1, ignore_index=False)
# 결과에서 date를 x축으로 실측 sales와 lstm의 결과를 y로 두고 비교
result_df.set_index('date').loc[:, ['sales', 'lstm']].plot()
결과치에 약간 차이가 있지만, 대체로 비슷한 모양을 그린다. 아마도 해마다 증분되는 경향을 제대로 반영하지 못하는 듯하다. 고민이 필요한 지점이지만 학습용이니 여기까지만..

'AI 빅데이터 > 후려치는 데이터분석과 AI 알고리즘' 카테고리의 다른 글
| [데이터분석] 주택가격 예측 Kaggle 도전기 (0) | 2020.09.25 |
|---|---|
| [데이터분석] GAN으로 수치 데이터 생성하기 (2) | 2020.09.17 |
| [데이터분석] 시계열분석 2 - XGBoost (1) | 2020.09.10 |
| [데이터분석] 시계열 분석 1 - ARIMA (937) | 2020.09.09 |
| [자연어 처리] Seq2Seq 로 자연어 번역하기 (0) | 2020.08.05 |




댓글