이전 포스팅에서는 상점 매출 데이터를 ARIMA로 분석하여 예측하는 것을 해 보았다.
[데이터분석] 시계열 분석 - ARIMA
기업 내 데이터분석이 많아지면서 자연스럽게 시계열분석에 대한 Needs가 많아졌다. 마케팅/구매/SCM 등 가치 사슬 내 거의 모든 부분이 시계열 데이터에 의존하고 있는데, 기존의 통계적 접근에��
magoker.tistory.com
이번에는 같은 데이터를 XGBoost로 분석/예측해본다. XGBoost는 수치형 데이터 분석에서는 현재 거의 끝판왕과 같다. H2O나 DataRobot을 통해 Auto ML을 수행하면 최적 모델이 거의 XGBoost나 같은 계열인 LightGBM으로 선정된다. 여러 모델을 돌려 평균치를 가져오는 Bagging방식의 Random Forest와 달리, XGBoost는 이상치가 발견되는 Classifier에 가중치를 더 해주는 Boosting 방식의 앙상블 모델이다. AdaBoost와의 차이점은 가중치를 찾는 데 있어 Gradient Descent 알고리즘을 사용하여 학습 시간을 줄여주는 것이라 할 수 있다.
1) 전처리
이번에는 store/item 별로 예측을 수행할 수 있도록 학습해서 테스트 할 예정이다. 전처리 코드는 아래와 같다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime
import xgboost as xgb
from xgboost import plot_importance, plot_tree
from xgboost import XGBClassifier
df = pd.read_csv("data/train.csv")
df['date'] = pd.to_datetime(df['date'])
df = df.set_index('date')
# store / item 별로 월별 판매를 합산
df = df.groupby(['store', 'item'])['sales'].resample('M').sum()
df = df.reset_index()
df = df.set_index('date')
df['month'] = df.index.month
df['year'] = df.index.year
df['dayofweek'] = df.index.dayofweek
# 학습과 테스트 데이터 분리
split = "2017-01-01"
df_train = df[:split]
df_test = df[split:]
df_train_y = df_train.loc[:,'sales']
df_train_x = df_train.drop('sales', axis=1)
df_test_y = df_test.loc[:,'sales']
df_test_x = df_test.drop('sales', axis=1)
# 나중에 예측값과 비교하기 위해 test 데이터 복제본 저장
df_test_orig = df_test.loc[:, ['store', 'item', 'sales']]
2) 학습
학습은 xgboost package의 xgb 패키지의 XGBRegressor모듈을 이용해 회귀 분석한다.
XG_model_month = xgb.XGBRegressor(n_estimators=1000)
XG_model_month.fit(df_train_x, df_train_y, eval_set=[(df_test_x, df_test_y)], early_stopping_rounds=50,verbose=False)
# 주요하게 적용하는 변수를 판단
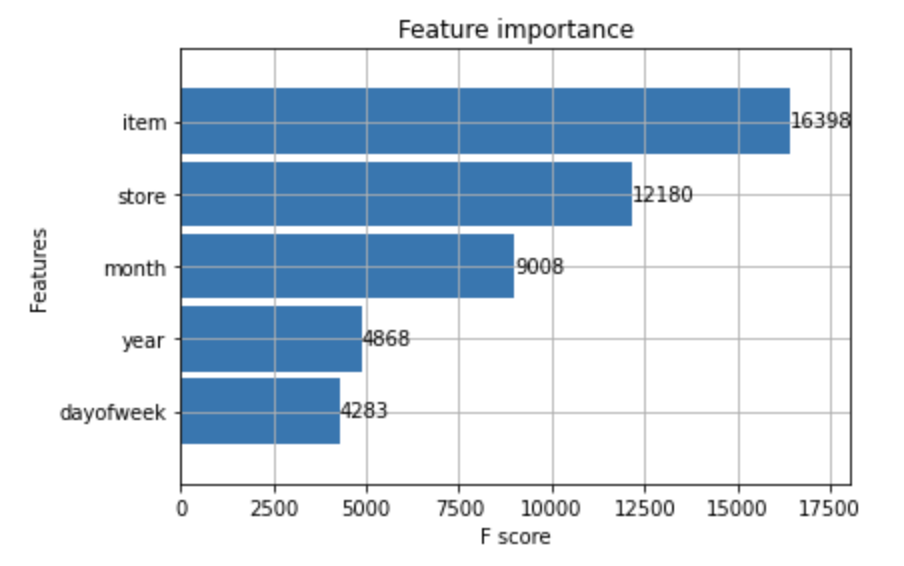
plot_importance(XG_model_month, height=0.9)
plot_importance는 결과에 주요하게 영향 주는 변수를 판단한다. 예상대로 item과 store, 그리고 month가 주요하게 취급된다.
3) 결과 예측
store/item 별로 테스트 데이터를 추출하여 예측 결과를 확인할 수 있다.
# 테스트 데이터 중 특정 store/item 데이터를 추출
df1 = df_test_x[(df_test_x.store==1) & (df_test_x.item==2)]
xgboost = XG_model_month.predict(df1)
# 실제 값과 예측 값을 하나의 DataFrame으로 만들고 visualize
result=pd.concat([df_test_orig[(df_test_orig.store==1)&(df_test_orig.item==2)].reset_index(), pd.DataFrame(xgboost, columns=['xgboost'])], axis=1, ignore_index=False)
result = result.set_index('date')
result = result.loc[:, ['sales', 'xgboost']]
result.plot()
예측력 높게 결과를 뽑아내고 있음이 확인된다.

'AI 빅데이터 > 후려치는 데이터분석과 AI 알고리즘' 카테고리의 다른 글
| [데이터분석] GAN으로 수치 데이터 생성하기 (2) | 2020.09.17 |
|---|---|
| [데이터분석] 시계열 분석 3 - 딥러닝 (LSTM) (0) | 2020.09.10 |
| [데이터분석] 시계열 분석 1 - ARIMA (937) | 2020.09.09 |
| [자연어 처리] Seq2Seq 로 자연어 번역하기 (0) | 2020.08.05 |
| [자연어처리] 텍스트 생성으로 이해하는 RNN (0) | 2020.08.02 |




댓글