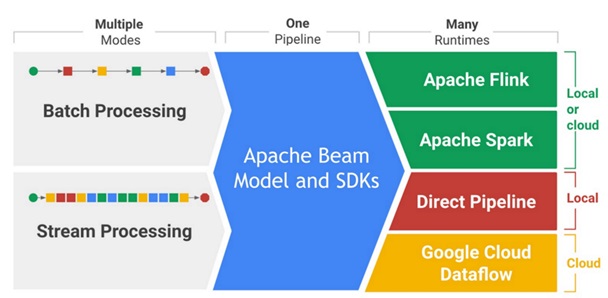
대량의 데이터를 전처리하는 건 많은 시간이 소요된다. Cloud 상에서 가용한 자원들을 동적으로 할당해서 좀 더 빠르게 해줄 수 있으면 좋은데, 병렬처리라는 게 또 공부하려면 만만찮아서인지 GCP에는 Cloud Dataflow라는 서비스가 이를 대신해 준다. Cloud Dataflow는 병렬로 실행시키는 일종의 흐름을 제어하는 서비스이고, 어떤 형태로 병렬 처리할지 그 구조를 Pipeline 형태로 잡아 놓는 것이 Google이 기증한 ‘Apache Beam’이 된다. Apache Beam으로 형성된 Pipeline은 Local에서 ‘DirectRunner’를 통해 수행(병렬처리는 안됨)하거나, Apache Flink 혹은 Spark로도 실행할 수 있다.
Beam의 예제로 자주 등장하는 단락 내에 단어 수 카운팅 하는 것을 예를 들어 사용해 보기로 한다.
import apache_beam as beam
from apache_beam.io import ReadFromText
from apache_beam.io import WriteToText
from apache_beam.metrics import Metrics
from apache_beam.metrics.metric import MetricsFilter
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.options.pipeline_options import SetupOptions
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "/home/ryu_gcloud2/dataflow_test/test-projector.json"
Google Cloud Dataflow에서 실행결과를 보려면 Application에 대한 Credential을 미리 만들어 두어야 하는데, 아래 조대협님 게시글에서 서비스키를 만드는 법을 참조(게시물의 중간쯤)한다. 만든 키는 GCP의 특정 디렉토리 옮겨두고 위에 그 경로를 적어두면 된다.
Application Credential
pipeline_options = PipelineOptions(None)
DEST_DIR = "gs://tf-bucket-ksryu/"
options = {
'staging_location': DEST_DIR + 'staging',
'temp_location': DEST_DIR + 'tmp',
'job_name': job_name,
'project': 'brave-cursor-255906', #project id
'zone' : 'us-central1-a',
'teardown_policy': 'TEARDOWN_ALWAYS',
'no_save_main_session': True ,
'save_main_session': False
}
opts = beam.pipeline.PipelineOptions(flags=[], **options)
Pipeline Option을 위와 같이 만들어주면 된다. 결과를 GCP에 저장해 둘 것이므로 GCS에 Bucket하나를 만들고, 단계별 결과물이 저장될 디렉토리를 지정해둔다. save_main_session 부분은 마지막에 run한 결과물을 저장해두는 것 같은데, 모듈의 반복 수행시 error를 일으키므로 개발단계에서는 False로 두었다. (정확한 의미는 사실 잘모름 ^^;;)
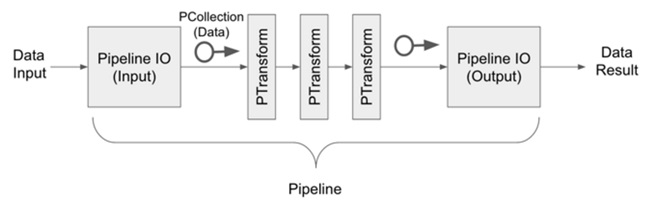
Apache Beam의 예제보다는 아주 살짝 단순하게, King_lear 단락과 king john에 대한 단락 두 개를 읽어서 처리하도록 하였다. 실제 파이프라인의 구조를 잡는 부분은 아래가 전부다. Beam의 PCollection이라는 개체를 인자로 받아 PTransform이라는 모듈이 변형하고 다시 Output으로 PCollection을 내보내는 구조다. 즉 아래의 함수들이 Transform하는 것이 PCollection의 데이터들이 Transform을 거치는 동안 다른 형태의 PCollection이 되는 것이다.
DATA_FILE1 = 'gs://dataflow-samples/shakespeare/kinglear.txt'
DATA_FILE2 = 'gs://dataflow-samples/shakespeare/kingjohn.txt'
p = beam.Pipeline('DataflowRunner', options=opts)
for step in ['lear', 'john']:
if step == 'lear':
DATA_FILE = DATA_FILE1
else:
DATA_FILE = DATA_FILE2
(p
| '{}_read'.format(step) >> ReadFromText(DATA_FILE)
| '{}_split'.format(step) >> (beam.ParDo(WordExtractingDoFn()).with_output_types(unicode))
| '{}_pair_with_one'.format(step) >> beam.Map(lambda x: (x, 1))
| '{}_group'.format(step) >> beam.GroupByKey()
| '{}_count'.format(step) >> beam.Map(count_ones)
| '{}_format'.format(step) >> beam.Map(format_result)
| '{}_write'.format(step) >> WriteToText(DEST_DIR + 'output')
)
위가 전체적인 구조로, Pipeline은 Cloud Dataflow가 후에 실제적인 작업을 진행할것으로 지정(DataflowRunner, Local로 수행하려면 DirectRunner)했다. 중간의 각 함수들이 실제로 Transform하는 모듈로 이 부분을 원하는 대로 구현해 주어야 한다. 참고로, ParDo가 필요시 리소스를 늘려서 병렬처리할 수 있도록 해 주는 부분인데, 본 예제에서는 데이터 처리량이 그리 크지 않아서 CPU를 1개 이상쓰진 않는다. ParDo가 쓰인 부분은 전체 문장에서 단어들을 분해하하여 돌려주는 모듈이다.
class WordExtractingDoFn(beam.DoFn):
"""Parse each line of input text into words."""
def __init__(self):
# TODO(BEAM-6158): Revert the workaround once we can pickle super() on py3.
# super(WordExtractingDoFn, self).__init__()
beam.DoFn.__init__(self)
self.words_counter = Metrics.counter(self.__class__, 'words')
self.word_lengths_counter = Metrics.counter(self.__class__, 'word_lengths')
self.word_lengths_dist = Metrics.distribution(
self.__class__, 'word_len_dist')
self.empty_line_counter = Metrics.counter(self.__class__, 'empty_lines')
def process(self, element):
"""Returns an iterator over the words of this element.
The element is a line of text. If the line is blank, note that, too.
Args:
element: the element being processed
Returns:
The processed element.
"""
text_line = element.strip()
if not text_line:
self.empty_line_counter.inc(1)
words = re.findall(r'[\w\']+', text_line, re.UNICODE)
for w in words:
self.words_counter.inc()
self.word_lengths_counter.inc(len(w))
self.word_lengths_dist.update(len(w))
return words
beam.DoFn Class를 상속하여 쓰면 되는데 process 함수를 overriding하여 필요한 코드를 작성하면 된다. 위의 예에서는 re.findall로 매 라인의 단어들을 분리하여 리턴하고 있다.
파이프라인에서 나머지 처리 모듈은 단어들을 grouping하여 수를 세고, 특정 format으로 만들어 출력하는 부분이다.
def count_ones(word_ones):
(word, ones) = word_ones
return (word, sum(ones))
def format_result(word_count):
(word, count) = word_count
return '%s: %d' % (word, count)
마지막으로 생성된 파이프라인을 Dataflow로 수행하도록 설정하면 Cloud Dataflow가 업무(?)를 시작한다.
result = p.run()
result.wait_until_finish()
처리가 끝나면 ‘Done’메시지가 출력되고, GCP의 Cloud Dataflow는 그 경과를 보여주며 GCS의 Bucket에는 결과물과 중간 단계의 파일들이 저장된다.

bow: 3
scurvy: 1
Importune: 1
forked: 1
embossed: 1
import: 1
day: 7
never: 26
profess: 3
covering: 1
Stain: 1
rare: 1
sing: 2
spring: 2
Ay: 17
ACT: 26
giant: 1
Methinks: 7
cure: 2
troops: 1
bolds: 1
sung: 1
wert: 2
wine: 1
enemies': 1
From: 11
V: 6
'Tis: 24
relieve: 1
resume: 1
beat: 3
Cost: 1
thing: 21
fish: 1
reading: 1
arrives: 1
....'AI 빅데이터 > Google Cloud Platform' 카테고리의 다른 글
| [GCP] 청구된 비용 환불 요청하기 (11) | 2020.03.04 |
|---|---|
| [GCP] Argo로 Workflow 만들기 (0) | 2020.03.04 |
| [GCP] 터미널에서 kubectl 사용하기 (0) | 2020.03.04 |
| [GCP] Flask로 TF 2.0 MNIST 모델 서빙하기 (0) | 2020.03.04 |
| [GCP] Putty Setup 하기 (987) | 2020.03.04 |



댓글