Langchain으로 간단히 PPT 있는 내용을 읽어서 대답을 생성해 주는 Bot을 Streamlit과 Gemini로 만들었다. Gemini는 Google AI Studio의 무료 계정을 사용했다.
1. ChatGoogle GenerativeAI import
import os
import streamlit as st
import os
os.environ["GOOGLE_API_KEY"] = "you api key"
from langchain_google_genai import (
ChatGoogleGenerativeAI,
HarmBlockThreshold,
HarmCategory,
)
st.title("PPT-Bot")
2. LangChain Module Import
from langchain.text_splitter import CharacterTextSplitter
from langchain.storage import LocalFileStore
from langchain_community.document_loaders import UnstructuredPowerPointLoader
from langchain.document_loaders import UnstructuredFileLoader
from langchain_google_genai import GoogleGenerativeAIEmbeddings
from langchain.embeddings import CacheBackedEmbeddings
from langchain.vectorstores import FAISS
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.chains import RetrievalQA
3. Loading Document
def load_doc():
cache_dir = LocalFileStore("./.cache/practice/")
splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
# PowerPoint Load
loader = UnstructuredPowerPointLoader("aaaa.pptx")
raw_docs = loader.load()
# Text Splitter를 사용할 때.
docs = splitter.split_documents(raw_docs)
# Splitter를 사용하지 않으려면 raw_docs를 Return한다
return docs, cache_dir
4. Retriever 생성
def get_retriever(docs, cache_dir):
embeddings = GoogleGenerativeAIEmbeddings(model="models/embedding-001")
# Cached Embedding 형태로 저장할 때
cached_embeddings = CacheBackedEmbeddings.from_bytes_store(embeddings, cache_dir)
# Chached Embedding 사용 시 (FAISS 사용)
# Cached embedding을 위해서는 아래 인자에 cached_embeddings를 넘겨준다.
vectorstore = FAISS.from_documents(docs, embeddings)
retriever = vectorstore.as_retriever()
return retriever
Vector DB인 FAISS를 사용하고, Retriever를 Return 한다. Embedding을 사용할 때, Cached Embedding을 사용하면, 임베딩을 저장하여 다시 계산할 필요가 없도록 해 준다.
5. LangChain 구성
def set_chain(retriever):
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""
You are a helpful assistant.
Answer questions using only the following context.
If you don't know the answer just say you don't know, don't make it up:
\n\n
{context}",
"""
),
("human", "{question}"),
]
)
chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="map_rerank",
retriever=retriever,
)
return chain
chain type에서 map_rerank는 여러 답변을 내놓고 score를 같이 돌려주는 방식이다.
6. 응답생성 함수
def generate_response(input_text):
st.info(chain.run(input_text))
7. 실행
# llm 객체 생성
llm = ChatGoogleGenerativeAI(model="gemini-pro",
safety_settings={
HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_NONE,
},)
# document loading / retrieval retrun / chain 설정
doc, cache = load_doc()
retriever = get_retriever(doc, cache)
chain = set_chain(retriever)
print("model loaded..")
# Input을 받고
with st.form('my_form'):
text = st.text_area('Enter text:', 'What are the three key pieces of advice for learning how to code?')
submitted = st.form_submit_button('Submit')
# submit이 눌려지면 응답될 때까지 spinner를 돌려주고, 응답생성
if submitted:
with st.spinner("답을 찾고 있습니다"):
generate_response(text)
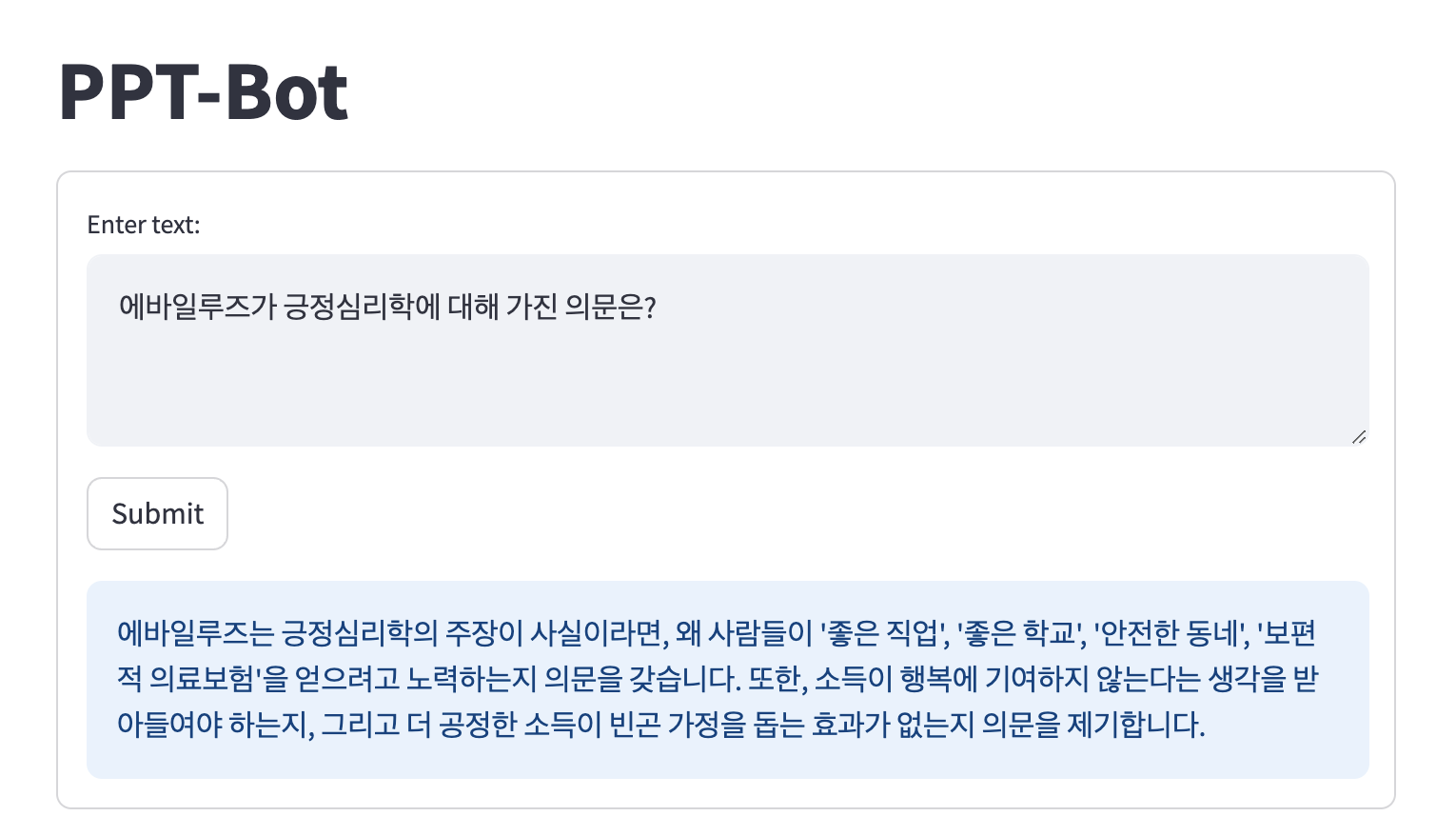
테스트로는 긍정심리학을 설명하고 있는 PPT파일을 사용했다. 긍정심리학에 대한 설명은 여기에
CacheBackedEmbedding을 사용하지 않는 경우가 더 대답을 잘하는데, 원인은 파악하지 못했다. 간단한 수행결과는 아래와 같다.

'AI 빅데이터 > AI 동향' 카테고리의 다른 글
| LLM을 QLoRA로 파인 튜닝 하기 (1) | 2023.11.24 |
|---|---|
| [AI가속] TensorRT-LLM (0) | 2023.10.25 |
| [Inference] WebGPU (0) | 2023.10.25 |
| [LLM 개발] Colab에서 허깅페이스 오픈 모델 사용 (0) | 2023.10.07 |
| [LangChain] VertexAI의 LLM으로 Web검색 연동하기 (1) | 2023.08.24 |



댓글